摘要: 谷歌开源的AI开发工具TensorFlow,了解一下?
谷歌的AI技术独步天下,从即将商业化运营的无人驾驶汽车Waymo ,到天下无敌的围棋大师AlphaGo ,再到以假乱真的电话助理Duplex …
如果你想学习AI技术的话,神经网络是个不错的学习方向,因为它是最神奇也是现在最有效的机器学习算法;如果你想学习神经网络的话,最好的起点是实现一个简单的神经网络,因为你可以在实现的过程中发现问题,思考问题以及解决问题;如果你想实现一个简单的神经网络的话,本文将教你使用TensorFlow来实现;至少,你可以直接运行本文给出的例子,感受一下神经网络的神奇。
TensorFlow简介 TensorFlow 是谷歌开源的AI开发工具,可以用于实现普通的机器学习算法(linear regression,logistic regression),也可以用于实现深度学习算法(各种不同类型的神经网络)。TensorFlow为深度学习进行了大量优化,使用TensorFlow提供的API,AI开发者能够更加简单地实现神经网络算法。
鸢尾花分类 下图是3种不同的鸢尾花,从左至右分别是setosa, virginica和versicolor。3种鸢尾花的花萼和花瓣的长宽各有不同。
iris_training.csv 是训练数据,它提供了120个鸢尾花的花萼和花瓣的长宽数据,并且标记了所属的鸢尾花类别。
根据训练数据,你可以总结出鸢尾花的花萼和花瓣的长宽与其所属类别的关系吗?120个数据不算太多,但是对人来说并不简单。
在本文中,我们将使用TesorFlow训练一个简单的神经网络,来识别鸢尾花的类别。
代码解释 train.py 训练神经网络的代码:
from __future__ import absolute_import, division, print_functionimport osimport tensorflow as tfimport tensorflow.contrib.eager as tfefrom parse_csv import parse_csvos.environ['TF_CPP_MIN_LOG_LEVEL' ] = '2' tf.enable_eager_execution() TRAIN_DATASET = tf.data.TextLineDataset("/tensorflow-101/data/iris_training.csv" ) TRAIN_DATASET = TRAIN_DATASET.skip(1 ) TRAIN_DATASET = TRAIN_DATASET.map(parse_csv) TRAIN_DATASET = TRAIN_DATASET.shuffle(buffer_size=1000 ) TRAIN_DATASET = TRAIN_DATASET.batch(32 ) MODEL = tf.keras.Sequential([ tf.keras.layers.Dense(10 , activation="relu" , input_shape=(4 ,)), tf.keras.layers.Dense(10 , activation="relu" ), tf.keras.layers.Dense(3 ) ]) def loss (model, x, y) : y_ = model(x) return tf.losses.sparse_softmax_cross_entropy(labels=y, logits=y_) def grad (model, inputs, targets) : with tf.GradientTape() as tape: loss_value = loss(model, inputs, targets) return tape.gradient(loss_value, MODEL.variables) OPTIMIZER = tf.train.GradientDescentOptimizer(learning_rate=0.01 ) def train () : print("训练:" ) num_epochs = 201 for epoch in range(num_epochs): epoch_loss_avg = tfe.metrics.Mean() epoch_accuracy = tfe.metrics.Accuracy() for x, y in TRAIN_DATASET: grads = grad(MODEL, x, y) OPTIMIZER.apply_gradients(zip(grads, MODEL.variables), global_step=tf.train.get_or_create_global_step()) epoch_loss_avg(loss(MODEL, x, y)) epoch_accuracy(tf.argmax(MODEL(x), axis=1 , output_type=tf.int32), y) if epoch % 50 == 0 : print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}" .format(epoch, epoch_loss_avg.result(), epoch_accuracy.result())) return MODEL
由代码可知,从导入训练数据,到定义神经网络模型的层数以及激励函数,再到定义损失计算函数、梯度计算函数和优化器,都使用了TensorFlow提供的API。这样,开发者不再需要去实现底层的细节,可以根据需要灵活地调整神经网络的结构以及所使用的各种函数。
其中,定义神经网络的代码如下:
MODEL = tf.keras.Sequential([ tf.keras.layers.Dense(10 , activation="relu" , input_shape=(4 ,)), tf.keras.layers.Dense(10 , activation="relu" ), tf.keras.layers.Dense(3 ) ])
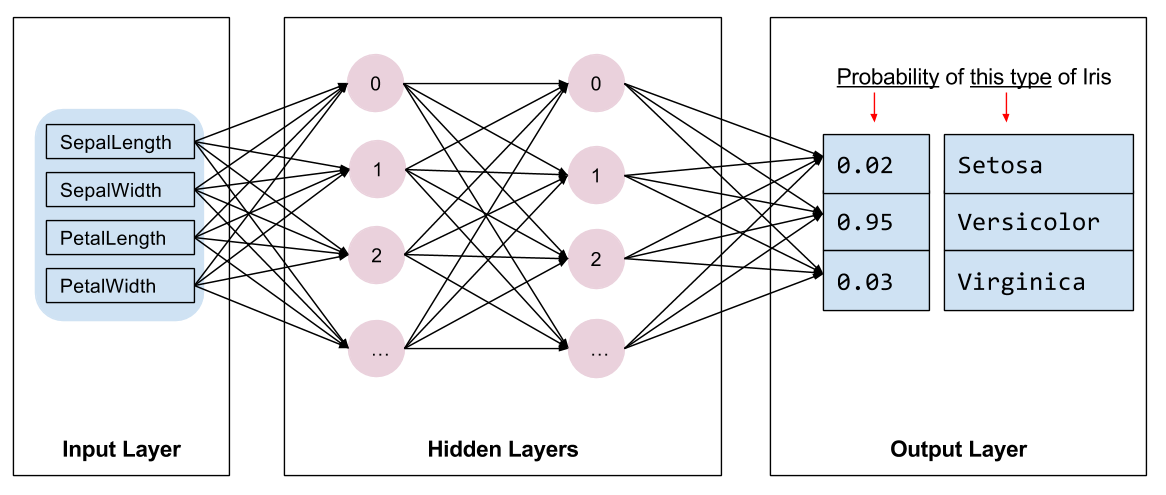
可知,这是一个4层的神经网络,包含1个输入层,2个隐藏层和1个输出层,2个隐藏层都有10个神经元,使用RELU作为激励函数,如下图所示:
训练代码最核心的是部分train 函数:
def train () : print("训练:" ) num_epochs = 201 for epoch in range(num_epochs): epoch_loss_avg = tfe.metrics.Mean() epoch_accuracy = tfe.metrics.Accuracy() for x, y in TRAIN_DATASET: grads = grad(MODEL, x, y) OPTIMIZER.apply_gradients(zip(grads, MODEL.variables), global_step=tf.train.get_or_create_global_step()) epoch_loss_avg(loss(MODEL, x, y)) epoch_accuracy(tf.argmax(MODEL(x), axis=1 , output_type=tf.int32), y) if epoch % 50 == 0 : print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}" .format(epoch, epoch_loss_avg.result(), epoch_accuracy.result())) return MODEL
train 函数的算法是这样的:
迭代计算200个epoch,每一个epoch迭代都会扫描整个训练数据集; 每个epoch中,会iterate整个训练数据集中的120个样本,其batch size为32,所以一个epoch需要4个iteration; 每个iteration中,根据样本的特征值(花萼和花瓣的长宽),使用神经网络做出预测(所属鸢尾花类别),与真实的标记值进行比较,计算损失及梯度。 每个iteration中,根据所计算的梯度,使用优化器修改神经网络中的参数值。 经过200个epoch,神经网络中的参数将会调整到最优值,使得其预测结果误差最低。 基于Docker运行TensorFlow 将TensorFlow以及代码都打包到Docker镜像中,就可以在Docker容器中运行TensorFlow。这样,开发者仅需要安装Docker,而不需要安装TensorFlow;同时,Docker保证了代码一定可以在任何Docker主机上正确执行,因为它所依赖的运行环境全部打包在Docker镜像中。Docker镜像使用Dockerfile 定义。
克隆代码 git clone https://github.com/Fundebug/tensorflow-101.git cd tensorflow-101
构建镜像 sudo docker build -t tensorflow .
运行容器 sudo docker run -i tensorflow python src/main.py
运行结果 训练: Epoch 000: Loss: 1.142 , Accuracy: 29.167 % Epoch 050: Loss: 0.569 , Accuracy: 78.333 % Epoch 100: Loss: 0.304 , Accuracy: 95.833 % Epoch 150: Loss: 0.186 , Accuracy: 97.500 % Epoch 200: Loss: 0.134 , Accuracy: 98.333 % 测试: Test set accuracy: 96.667 % 预测: Example 0 prediction: Iris setosa Example 1 prediction: Iris versicolor Example 2 prediction: Iris virginica
由结果可知,对于测试数据集iris_test.csv ,所训练的神经网络的准确率高达96.667% ,是不是很神奇呢?
参考
关于Fundebug
Fundebug 专注于JavaScript、微信小程序、微信小游戏、支付宝小程序、React
Native、Node.js和Java线上应用实时BUG监控。
自从2016年双十一正式上线,Fundebug累计处理了30亿+错误事件,付费客户有阳光保险、达令家、核桃编程、荔枝FM、微脉等众多品牌企业。欢迎大家免费试用 !
版权声明:
转载时请注明作者KiwenLau https://kiwenlau.com/2018/06/06/tensorflow-101/