Run Hadoop Cluster in Docker Update
Abstract: Last year, I developed kiwenlau/hadoop-cluster-docker project, which aims to help user quickly build Hadoop cluster on local host using Docker. The project is quite popular with 250+ stars on GitHub and 2500+ pulls on Docker Hub. In this blog, I’d like to introduce the update version.
- Author: KiwenLau
- Date: 2016-06-26
Introduction
By packaging Hadoop into Docker image, we can easily build a Hadoop cluster within Docker containers on local host. This is very help for beginners, who want to learn:
- How to configure Hadoop cluster correctly?
- How to run word count application?
- How to manage HDFS?
- How to run test program on local host?
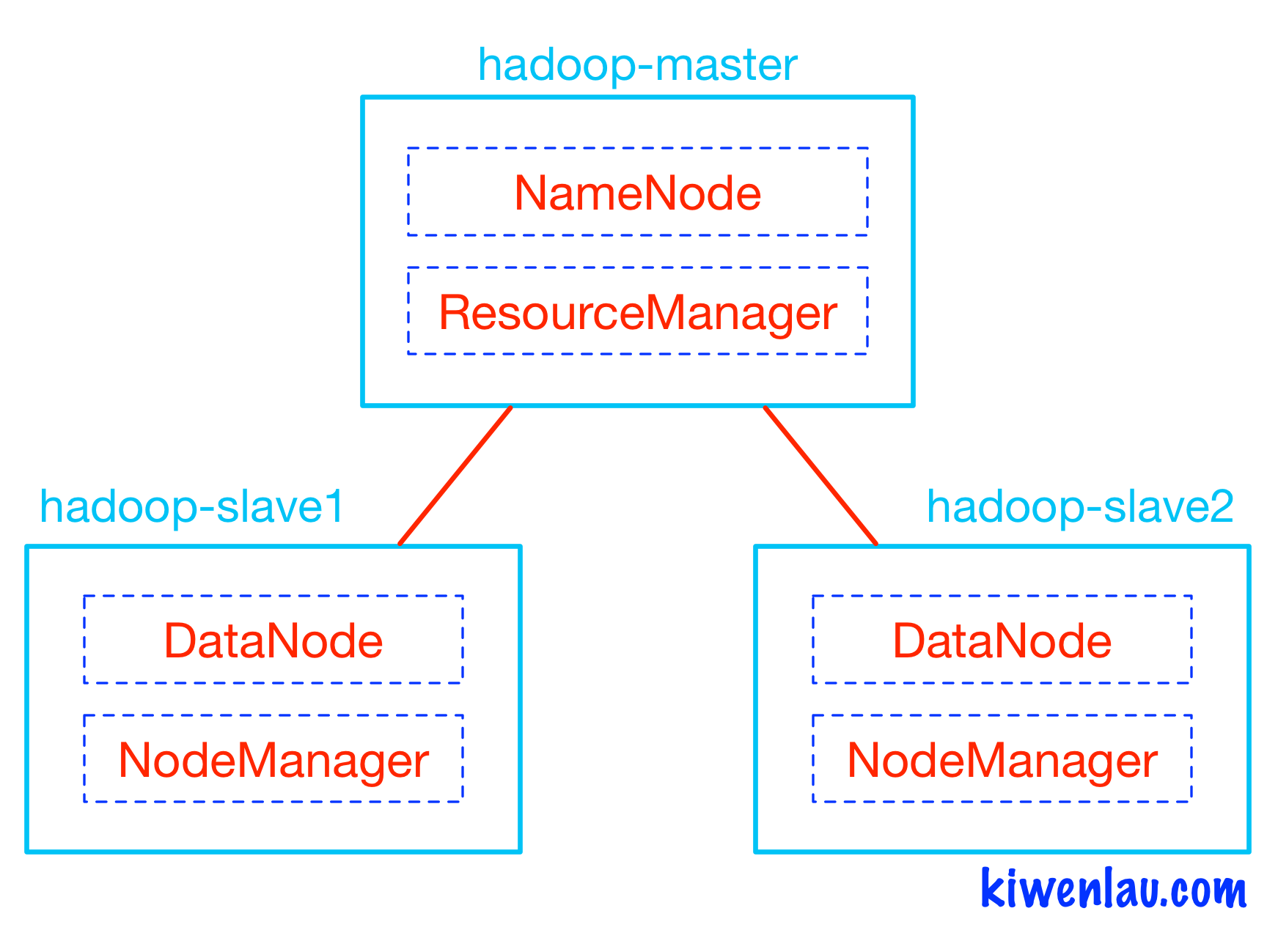
Following figure shows the architecture of kiwenlau/hadoop-cluster-docker project. Hadoop master and slaves run within different Docker containers, NameNode and ResourceManager run within hadoop-master container while DataNode and NodeManager run within hadoop-slave container. NameNode and DataNode are the components of Hadoop Distributed File System(HDFS), while ResourceManager and NodeManager are the components of Hadoop cluster resource management system called Yet Another Resource Manager(YARN). HDFS is in charge of storing input and output data, while YARN is in charge of managing CPU and Memory resources.
In the old version, I use serf/dnsmasq to provide DNS service for Hadoop cluster, which is not an elegant solution because it requires extra installation/configuration and it will delay the cluster startup procedure. Thanks to the enhancement of Docker network function, we don’t need to use serf/dnsmasq any more. We can create a independent network for Hadoop cluster using following command:
sudo docker network create --driver=bridge hadoop |
By using “–net=hadoop” option when we start Hadoop containers, these containers will attach to the “hadoop” network and they are able to communicate with container name.
Key points of update:
- eliminate serf/dnsmasq
- merge master and slave image
- install Hadoop using kiwenlau/compile-hadoop
- simplify Hadoop configuration
3 Nodes Hadoop Cluster
1. pull docker image
sudo docker pull kiwenlau/hadoop:1.0 |
2. clone github repository
git clone https://github.com/kiwenlau/hadoop-cluster-docker |
3. create hadoop network
sudo docker network create --driver=bridge hadoop |
4. start container
cd hadoop-cluster-docker |
output:
start hadoop-master container... |
- start 3 containers with 1 master and 2 slaves
- you will get into the /root directory of hadoop-master container
5. start hadoop
./start-hadoop.sh |
6. run wordcount
./run-wordcount.sh |
output
input file1.txt: |
Arbitrary size Hadoop cluster
1. pull docker images and clone github repository
do 1~3 like previous section
2. rebuild docker image
sudo ./resize-cluster.sh 5 |
- specify parameter > 1: 2, 3..
- this script just rebuild hadoop image with different slaves file, which pecifies the name of all slave nodes
3. start container
cd hadoop-cluster-docker |
- use the same parameter as the step 2
4. run hadoop cluster
do 5~6 like previous section
References
关于Fundebug
Fundebug专注于JavaScript、微信小程序、微信小游戏、支付宝小程序、React Native、Node.js和Java线上应用实时BUG监控。 自从2016年双十一正式上线,Fundebug累计处理了30亿+错误事件,付费客户有阳光保险、达令家、核桃编程、荔枝FM、微脉等众多品牌企业。欢迎大家免费试用!

版权声明: 转载时请注明作者KiwenLau以及本文地址: https://kiwenlau.com/2016/06/26/hadoop-cluster-docker-update-english/
